14. Kokkos and Virtual Functions#
Due to oddities of GPU programming, the use of virtual functions in Kokkos parallel regions can be complicated. This document describes the problems you’re likely to face, where they come from, and how to work around them.
The Problem#
In GPU programming, you might have run into the bug of calling a host function from the device. A similar thing can happen for subtle reasons in code using virtual functions. Consider the following code
class ClassWithVirtualFunctions : public SomeBase {
/** fields */
public:
KOKKOS_FUNCTION virtual void virtualFunction(){
// TODO: implement all of physics
}
};
ClassWithVirtualFunctions* hostClassInstance = new hostClassInstance();
ClassWithVirtualFunction* deviceClassInstance;
cudaMalloc((void**)&deviceClassInstance, sizeof(ClassWithVirtualFunction));
cudaMemcpy(deviceClassInstance, hostClassInstance, sizeof(ClassWithVirtualFunction), cudaMemcpyHostToDevice);
Kokkos::parallel_for("DeviceKernel", SomeCudaPolicy, KOKKOS_LAMBDA(const int i) {
deviceClassInstance->virtualFunction();
});
At a glance this should be fine, we’ve made a device instance of a class, copied the contents of a host instance into it, and then used it. This code will typically crash, however, because virtualFunction will call a host version of the function. To understand why, you’ll need to understand a bit about how virtual functions are implemented.
V-Tables, V-Pointers, V-ery annoying with GPUs#
Virtual functions allow a program to handle Derived classes through a pointer to their Base class and have things work as they should. To make this work, the compiler needs some way to identify whether a pointer which is nominally to a Base class really is a pointer to the Base, or whether it’s really a pointer to any Derived class. This happens through VPointers and VTables. For every class with virtual functions, there is one VTable shared among all instances, this table contains function pointers for all the virtual functions the class implements.

Okay, so now we have VTables, if a class knows what type it is it could call the correct function. But how does it know?
Remember that we have one VTable shared amongst all instances of a type. Each instance, however, has a hidden member called the VPointer, which on initialization the compiler points at the correct table. So a call to a virtual function simply dereferences that pointer, and then indexes into the VTable to find the precise virtual function called.
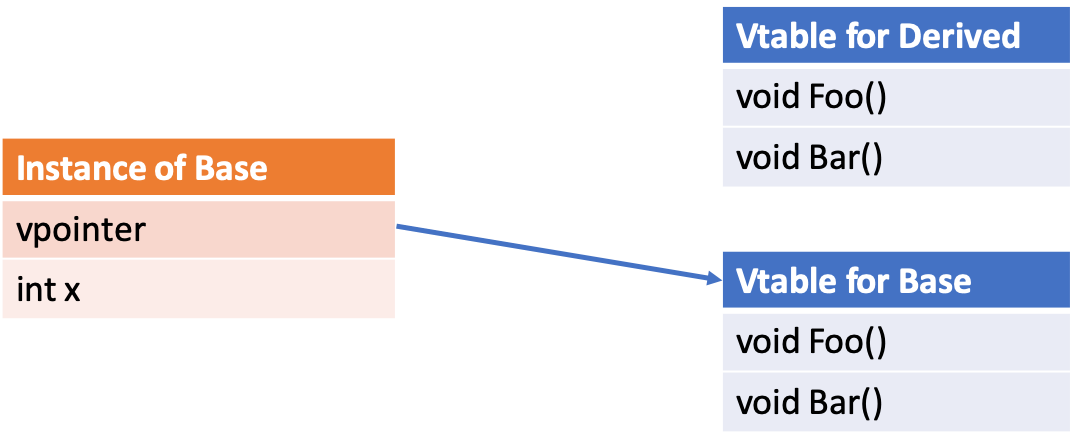
Now that we know what the compiler is doing to implement virtual functions, we’ll look at why it doesn’t work with GPU’s
Credit: the content of this section is adapted from Pablo Arias here
Then why doesn’t my code work?#
The reason the intro code might break is that when dealing with GPU-compatible classes with virtual functions, there isn’t one VTable, but two. The first has the host versions of the virtual functions, while the second has the device functions. We’re initializing the class on the host, so it points to the host VTable.
Our cudaMemcpy faithfully copied all of the members of the class, including the VPointer merrily pointing at host functions, which we then call on the device.
How to fix this#
The problem here is that we are initializing the class on the Host. If we were initializing on the Device, we’d get the correct VPointer, and thus the correct functions. In pseudocode, we want to move from
Instance* hostInstance = new Instance(); // allocate and initialize host
Instance* deviceInstance; // cudaMalloc'd to allocate
cudaMemcpy(deviceInstance, hostInstance); // to initialize the deivce
Kokkos::parallel_for(... {
// use deviceInstance
});
To one where we initialize on the device using a technique called placement new
Instance* deviceInstance; // cudaMalloc'd to allocate it
Kokkos::parallel_for(... {
new((Instance*)deviceInstance) Instance(); // initialize an instance, and place the result in the pointer deviceInstance
});
This code is extremely ugly, but leads to a properly initialized instance of the class. Note that like with other uses of new, you need to later free the memory
For a full working example, see the example in the repo.
Complications and Fixes#
The first problem people run into with this is that they want to initialize some fields or nested classes based on host data before moving data down to the device
Instance* hostInstance = new Instance(); // allocate and initialize host
hostInstance->setAField(someHostValue);
Instance* deviceInstance; // cudaMalloc'd to allocate
cudaMemcpy(deviceInstance, hostInstance); // to initialize the deivce
Kokkos::parallel_for(... {
// use deviceInstance
});
We can’t translate this easily, the naive translation would be
Instance* deviceInstance; // cudaMalloc'd to allocate it
Kokkos::parallel_for(... {
new((Instance*)deviceInstance) Instance(); // initialize an instance, and place the result in the pointer deviceInstance
deviceInstance->setAField(someHostValue);
});
Which would crash for accessing the host value someHostValue on the device. The most productive solution we’ve found in these cases is to allocate the class in UVM, initialize it on the device, and then fill in fields on the host. To wit:
Instance* deviceInstance = Kokkos::kokkos_malloc<Kokkos::CudaUVMSpace>(sizeof(Instance));
Kokkos::parallel_for(... {
new((Instance*)deviceInstance) Instance(); // initialize an instance, and place the result in the pointer deviceInstance
});
deviceInstance->setAField(someHostValue); // set some field on the host
This is the solution that the code teams we have talked to have said is the most productive way to solve the problem.
Questions/Follow-up#
This is intended to be an educational resource for our users. If something doesn’t make sense or you have further questions, you’d be doing us a favor by letting us know on Slack or GitHub